Syndication and Simple REST XML web services in a library context
Sigfrid Lundberg's Stuff 2009-09-27![]()
a tonne of broken links below! to mend them would be a project on its own.
Some time ago I discussed our architecture for presenting some of our digitized material. We use a combination of opml and OpenSearch for letting our users search and navigate our Digital Editions. Opml is used for dissemination of the subject structure and for hierarchical tables of contents. Result set navigation is using open search. The system could be described as having two major architectural components, the database layer (Fig. 1) and the presentation layer (Fig. 2).
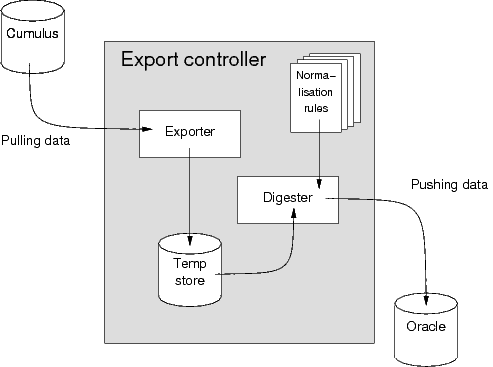
Fig. 1. Database layer. The export controller pulls data out of our Cumulous Digital Asset Management system, normalizes them to a single syntactical and semantical system, namely Metadata Object Description Schema (MODS). From that format it is further transformed into RSS 2.0 and Dublin Core. Finally these metadata objects are stored in our Oracle as XML fragments. The normalization rules are implemented as a set of XSLT scripts with a supporting set of xpath functions implemented in java.
Metadata processing
A couple of weeks ago, I accidentally searched the Web for "metadata processing". "Google suggest" invites you to that kind of serendipity. I've previously not been able to give a name to the discipline of one of my main areas of expertise; here we go. It's metadata processing. This phrase yields about 10.600 hits in a Google search, which makes it a smaller disciplin than sewage processing.
The database layer is all about metadata processing. Our Cumulus installation contains a multitude of metadata fields invented by people for particular purposes in the past. The main objective has been to get a job done and images into a database, not out on the web in an efficient way and not to get the metadata across to other services.

Fig. 2. Presentation layer. The presentation layer is really two layers, one Web service layer and one user step further away a graphical user interface which we refer to as an OpenSearch gateway. This is because OpenSearch is its main communication protocol with the web service layer.
In this project our goal was to be able to present this material in a single framework, using a homogenous metadata profile. The metadata core is built around Metadata Object Description Schema (MODS). The Export controller (Fig. 1) consists of two loosely connected components; the Exporter and the Digester. The former basically dumps data from Cumulus using its java API, the latter basically transforms those data into a range of XML fragment formats described in Table 1.
The basic idea is to avoid any stage where we have to generate XML from scratch later on in the process; processing of semi-manufactured XML objects is computationally much cheaper than the generation of new ones.
Web services
The web service layer (Fig. 2) does search and retrieval and operates basically by retrieving the XML fragments generated by the Digester (see above). The design goal has been to minimize the cost of XML processing here to a minimum. For the processing that occur there we use the Streaming API for XML (StAX) (JSR-173). StAX is standard from java sdk 1.6. It wasn't trivial to get it running for java 5.
When you just want to make modest stream editing of XML, this is an excellent tool. I doubt that you can ever get an as fast DOM based XML tool, so whenever possible use this. There are a few cases where we were forced to introduced XML and XSLT for more extensive editing, but in general here we use ligh-weight XML technology. We access Oracle through Hibernate, which was a pleasure when the mappings were in place -- but it is a nightmare to make the hibernate mappings if you're a beginner.
OpenSearch is my favourate XML protocol for searching, since it is much easier to use than SRU. You can direct test an OpenSearch implementation on on a9.com[dead]. You paste the URI of an opensearch description into their form and you'll then get back an interpretation of your data and a search form. Please try it![dead link]. Don't search for the suggested search term esbjerg, try something like "Adam".
The OAI service is already running, and for the first time our library catalog can retrieve and import bibliographical records from our digitization services automatically.
| function | format | example service |
|---|---|---|
| dissemination of metadata | MODS, oai_dc via OAI | http://www.kb.dk/cop/oai?verb=GetRecord&identifier=oai:kb.dk:Samlingsbilleder/100&metadataPrefix=oai_dc |
| syndication and search | RSS 2.0 and opensearch | http://www.kb.dk/images/billed/2008/sep/kistebilleder/en/?query=Adam*&itemsPerPage=40 |
| subject navigation | opml | http://www.kb.dk/cop/navigation/images/billed/2008/sep/kistebilleder |
| content navigation (via tables of contents) | opml | no edition available yet |
| REST Web service description Rudimentary collection level description |
OpenSearchDescription | http://www.kb.dk/cop/description/images/billed/2008/sep/kistebilleder |
| Configuration service | Java properties in XML. See also the DTD. | http://www.kb.dk/cop/configuration/images/billed/2008/sep/kistebilleder |
Presentation layer
The part of the system which users will actually see and use is best described as a mash-up engine. The basis is yet-another template system. I think that it is fair guess that each major web development platform already has more of those than they need. My problem was that I needed a recursive one.
The template is a XML document with include statements in certain places. The engine then retrieves data from the web services, transform the them and put the product in place with the XML DOM api. There will now be new include statements, which were the product of the previous set of data inserted. There are usually a handful of recursions before the page is ready for delivery. We have two skins or templates running, Danmarksbilleder [dead] and Default used for the services mentioned above. Apart from different look and feel, Danmarksbilleder uses an older version of the database and another set of web services. See my previous posting.
There are currently no plans to make new HTML skins. However, I'm about to write one that generates Metadata Encoding and Transmission Standard (METS) documents. But that's another story.
 Subscribe to my stuff
Subscribe to my stuffstuff by category || year
- About me
- Ageing
- Archival description
- Art
- Colophon
- Creative Commons
- Digital collections
- Digital libraries
- Digital Object
- Digitization
- Economics
- Digital humanities
- eScience
- Essays
- Flickr
- Food and drink
- Hardware
- Harvesting
- Images
- Internet
- Lenses
- Literature
- Media
- Metadata
- Metadata processing
- Mothers
- Music, language & literature
- Neighbours
- Digital Object Stores
- Library catalogues
- Open Content
- Photography
- Poetry
- Digital preservation
- Programming
- Religion
- Reviews
- Software
- Souvenir
- Spirituality
- Stories
- Structural web design
- Text encoding
- The Library
- Typography
- Video
- Web indexing
- XML processing
- XML technologies
- XML web services
- Z39.50
- Zeitgeist
NB
My name is Sigfrid Lundberg. The stuff I publish here may, or may not, be of interest for anyone else.
On this site there is material on photography, music, literature and other stuff I enjoy in life. However, most of it is related to my profession as an Internet programmer and software developer within the area of digital libraries. I have been that at the Royal Danish Library, Copenhagen (Denmark) and, before that, Lund university library (Sweden).
The content here does not reflect the views of my employers. They are now all past employers, since I retired 1 May 2023.

This entry (Syndication and Simple REST XML web services in a library context) within Sigfrid Lundberg's Stuff,
by
Sigfrid Lundberg
is licensed under a
Creative Commons
Attribution-ShareAlike 3.0 Unported License.